Further reading
This section covers a variety of different topics that we couldn’t fit into the main part of the course.
Creating your own R project
To ensure everyone is working in a consistent environment for this course, we pre-made an R project for you to use. But what if you want to make your own project, for another analysis?
Recall from session 1 that you can see all of your R projects and create a new one in the top right hand corner of RStudio:
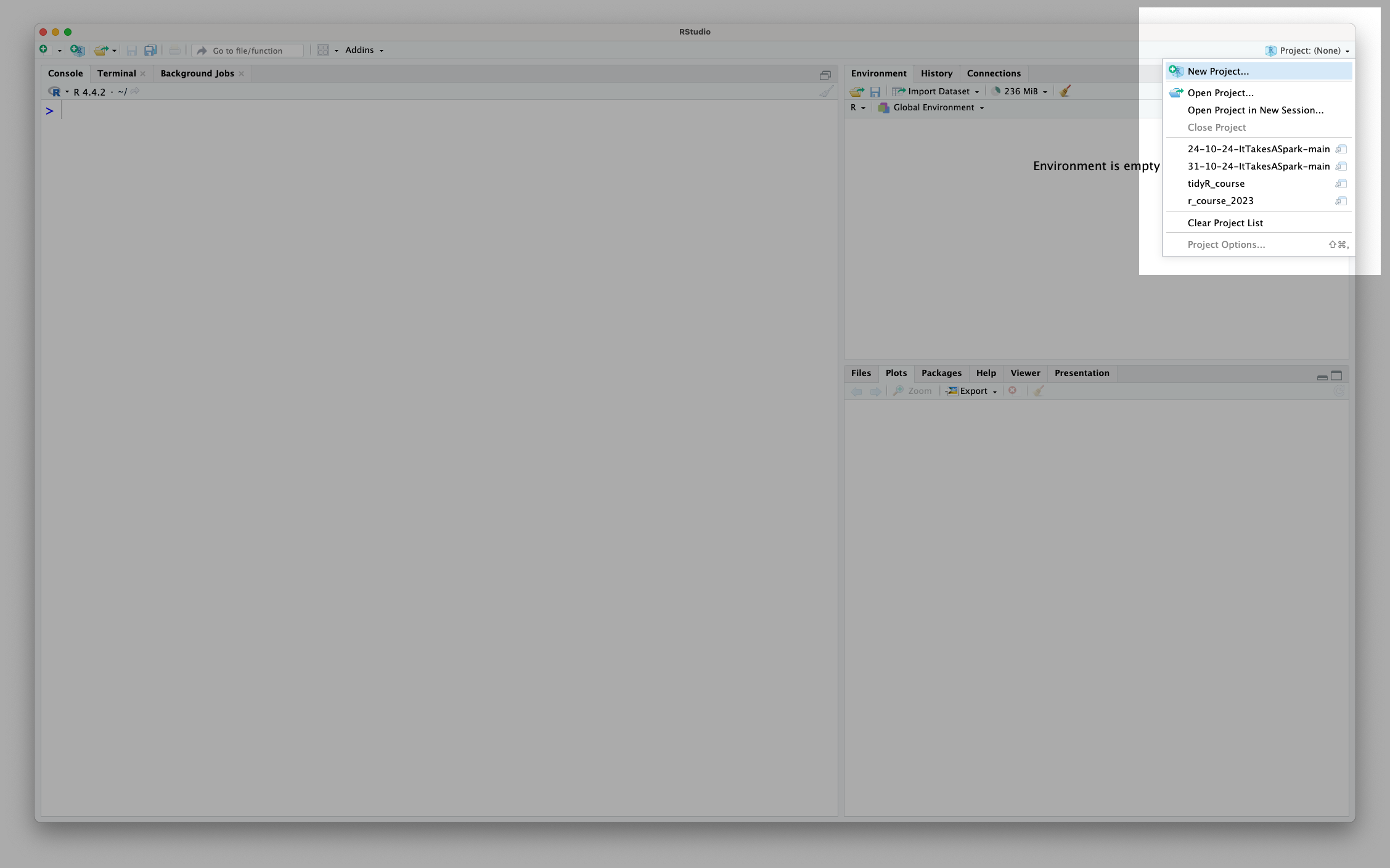
Usually, you want to create a new project in a new directory (folder) so that everything stays organised:
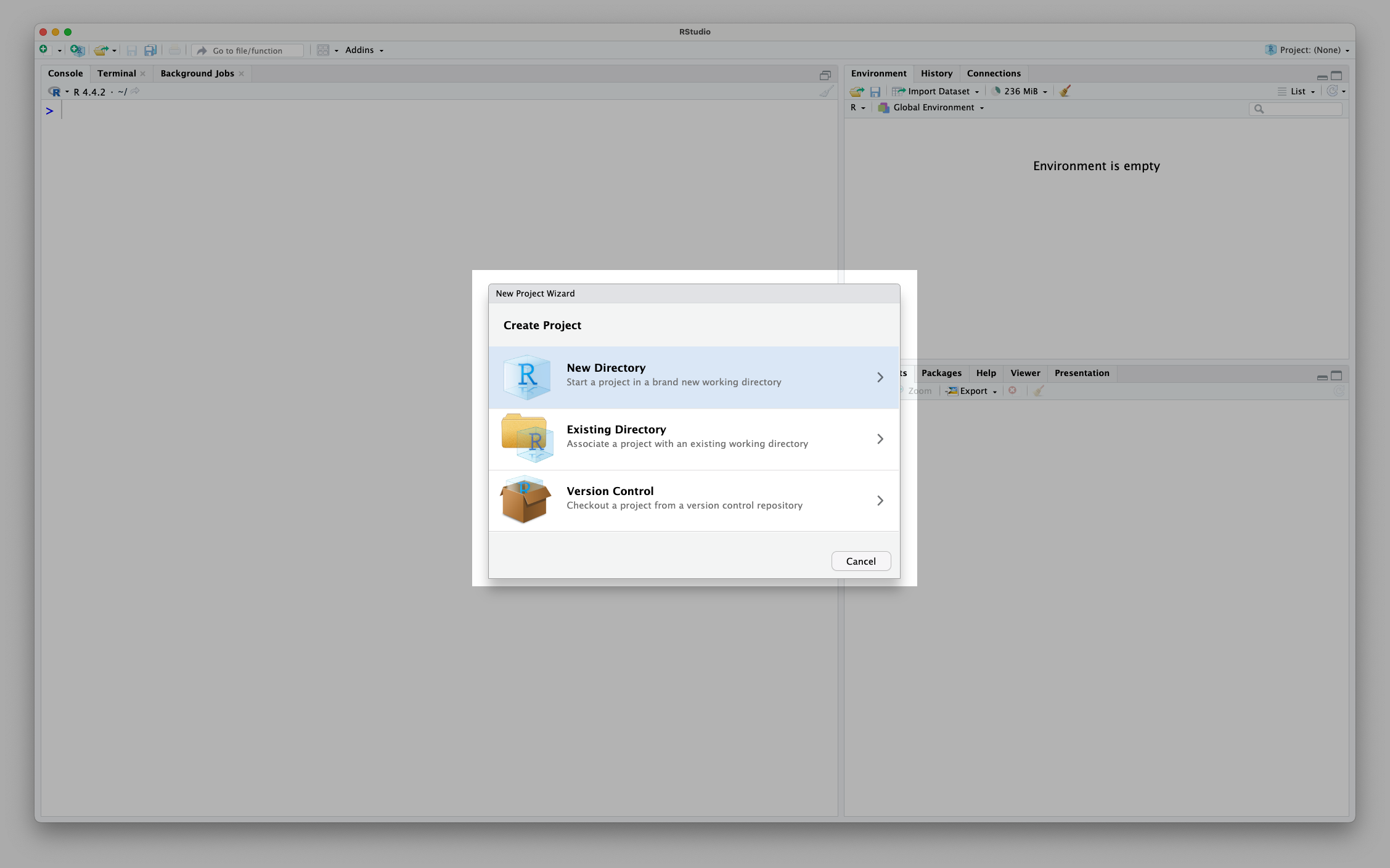
Next, we need to tell R that we want to make a ‘New Project’ and not any of the other fancy things we could create:
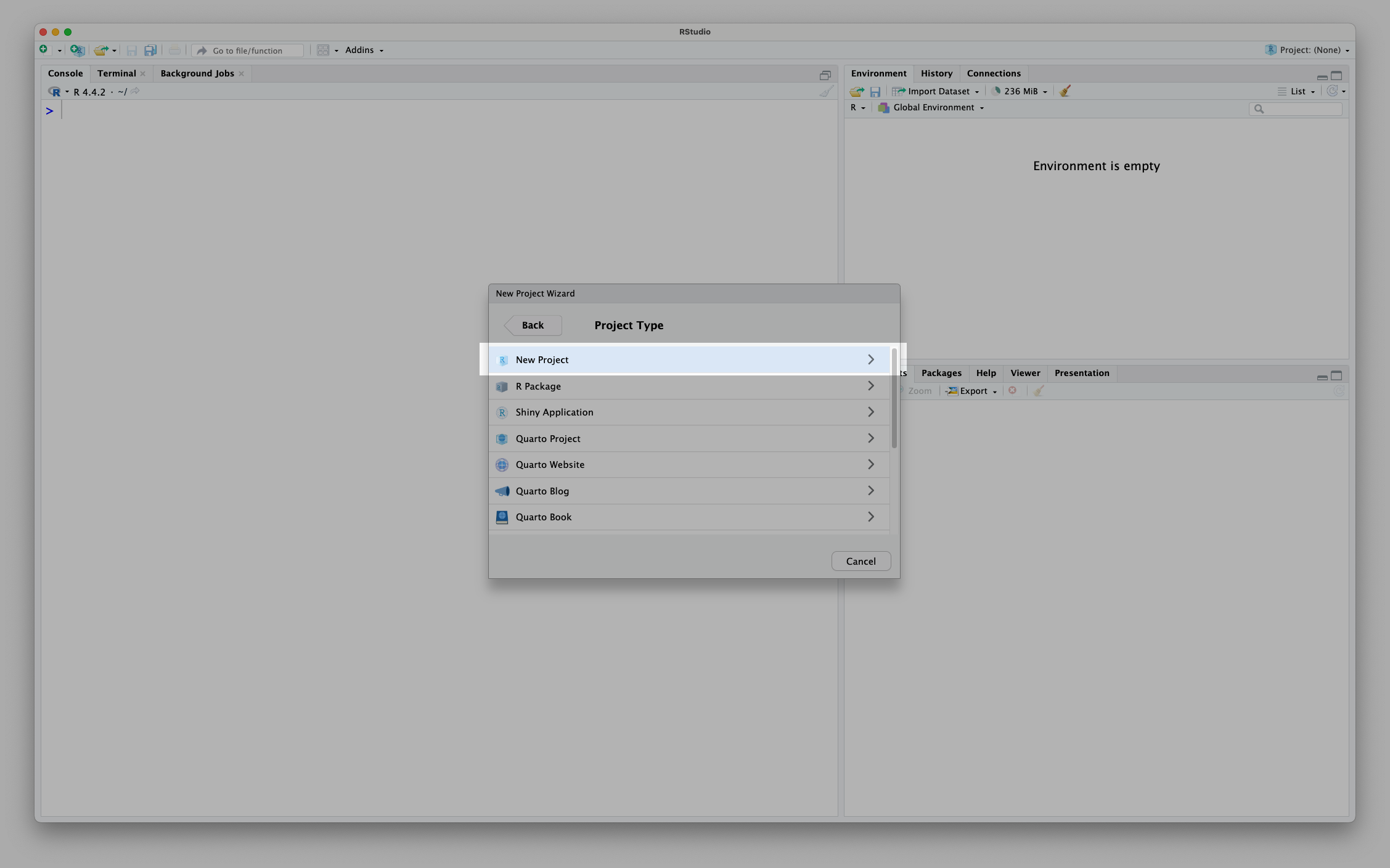
Finally, we need to give our project an informative name:
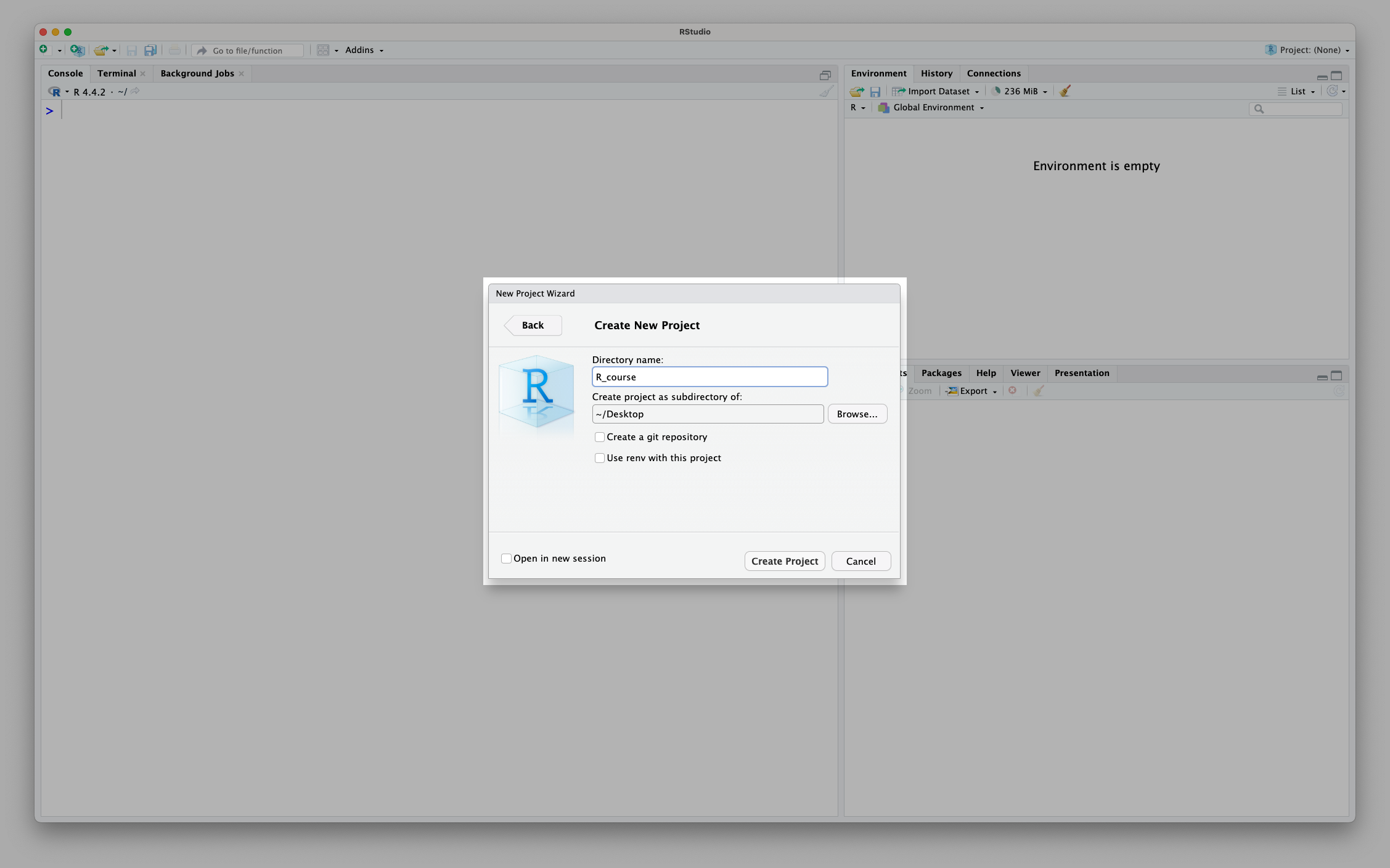
Don’t forget to name with underscores and not spaces!
Paths
We briefly touched on paths in the first session, but it is an important and complex topic that with worth digging into further. Paths are a way to specify the location of a file or directory on your computer, they are important whenever data needs to be read from or written to a file. This makes it a crucial concept for data analysis in R.
Absolute paths
An absolute path is defined as the full path from the root directory of the computer. These paths start with the root directory, which is / on Unix-based systems (like Linux and MacOS) and C:\ on Windows systems. For example, the absolute path to the home directory on a Unix-based system would be /home/my_username/analysis/data/file.txt. These paths should be used when the location of the file is not going to change and is in some shared location external to the project.
Relative paths
Relative paths are defined as a path relative to the current working directory. If you are already in the directory /home/users/my_username/analysis/, the relative path to the file data/file.txt would be have the same meaning as the absolute path /home/users/my_username/analysis/data/file.txt. Relative paths are useful when the location of the file is likely to change, for example if the whole analysis folder might be moved around with its included data.
Home directories
Users tend to have a home directory, which is the private directory each user is assigned. This directory is often located at /home/my_username/ on Unix-based systems and C:\Users\my_username\ on Windows systems. This directory commonly acts as the starting point for many paths local to the user, and can be referred to using the shortcut ~ (tilde). For example, the path ~/analysis/data/file.txt would be equivalent to /home/my_username/analysis/data/file.txt on a Unix-based system. The exact path that is referred to by ~ can be found by running the command Sys.getenv("HOME") in R, and is relative to the user running the R session.
The here package
There are situations where you want to organise your scripts into folders, and if you navigate to these folders and run the scripts, they will run within the folder they are in. But often you will want to run the script from the root folder of the project. For example if you have a script in ~/analysis/scripts/plot.R and inside you use data/file.txt to reference ~/analysis/data/file.txt, if you run the script from ~/analysis/scripts/ it will not find the file. The here package solves this problem by anchoring your paths relative to the root folder of the project. Details about the package can be found here.
Using AI helpers
There are a range of useful AI helpers available that can help solve problems with R. These include ChatGPT, Gemini, GitHub Copilot and more. However, it is important to remember that they are not perfect. This can have serious consequences if code provided by an AI helper contains a mistake that ends up affecting the analysis. It is therefore very important to both check the code provided by an AI as before you run it and inspect the result it produces to ensure it is reliable.
You should avoid:
- Running code from an AI helper without checking it first
- Running code from an AI helper without understanding the result it produces
- Copy and pasting large amounts of code from an AI helper without understanding it
- Copy and pasting confidential or patient data into AI helpers to get it to write you code
- Using an AI helper as a substitute for learning how to code
- Using an AI helper as a substitute for understanding the problem you are trying to solve
Because of the way AI helpers work, if you don’t understand a particular bit of code it produces, you can simply ask it to explain what it’s doing. If you don’t understand the explanation, or disagree with it, you should confront the AI helper with your concerns or check with a real-life bioinformatician (we don’t bite!). Only run the code once you are sufficiently convinced that it’s doing what you want.
To use AI effectively, it helps to provide as much context as possible. This includes but is not limited to:
- The problem you are trying to solve
- The data you are working with (or a de-identified description of it)
- The output you are expecting
- The code you have already tried
- The error messages you are getting
When asking questions of the AI, you should be as specific as possible while providing room for flexibility in the answer. It often helps to start with a broader question before narrowing in on the specific problem you are facing. For example a poor question would be too vague without enough context, such as “How do I plot differential expression data?” A better question could be “What plots are commonly used to visualise differential expression data in RNA-seq analysis?”. Followed by “How do I create a volcano plot in R using ggplot2?”. If you have differential expression data ready, you can also describe it to the AI helper to get more specific advice. For example “I have a a data frame with the columns gene, log2FoldChange and pvalue, how can I create a volcano plot from this data?”.
The more information you provide the AI, the more likely it is to provide a useful answer. If you are confused about how to use a specific function, instead of asking the AI “How do I use the … function from the … package?”, you can copy and paste the entire help page for the function into the AI chat along with a description of what you’re trying to do.